AI (人工智能): 配置
本地对象识别
Agent DVR 支持使用 AI 模型文件 (.onnx) 进行实时实时对象识别。您需要一个 许可证(或有效订阅)才能使用此功能。有关配置 Agent 以使用外部 AI 服务器的信息,请参见 AI 服务器。
要开始,请编辑您的摄像头并转到 对象识别 选项卡。在顶部选择您的 AI 服务器。默认设置为 内部,这是 Agent DVR 内置的 AI。如果您想使用 AI 服务器,请在服务器设置 - AI 设置 - AI 服务器中添加它,然后在此处选择。
以下详细信息用于配置 Agent DVR 及其快速内置 AI。您还可以添加任何其他您喜欢的模型,例如 Ultralytics YOLO 模型。
- 模型: 选择您想要使用的 AI 模型。Agent 将根据需要自动下载内置模型。微型模型适合低端硬件或大量摄像头。中型模型适合更好的准确性,但使用更多的处理能力。
- 模式: 选择您希望 AI 处理视频帧的时间。如果选择 间隔,Agent 将使用下面的 处理速率 字段持续分析您的视频流。
- 叠加: 勾选以在实时视频上绘制实时结果。这对于调整置信限非常有用。
- 模糊: 勾选此项以模糊识别的对象(例如,人)。
- 使用 GPU: 勾选此项以使用您的 GPU 而不是 CPU。
- 处理速率: 仅在 模式 为 间隔 时使用 - 它控制发送到模型的帧速率。输入 1 表示每秒 1 帧,20 表示每秒 20 帧,或 0.1 表示每 10 秒 1 帧。
- 置信度: 这过滤模型的结果。将其调高以减少误报,但请注意,它可能也会漏掉对象。
- 检查角落: 有关更多详细信息,请参阅 检查角落。
- 查找: 指定 AI 要检测的对象。此处的选项列表来自模型配置。
- 忽略静态对象: 忽略在同一位置重复发现的对象。
- 容差: 这控制对象在被标记为非静态之前可以移动多少。
- 从反馈中学习: 让 Agent 从您那里学习。启用此功能后,您可以在警报查看器中确认或拒绝检测,Agent 将学习抑制此摄像头上的类似误报。请参见 从反馈中学习。
自定义模型
要将您自己的模型添加到 AI,请将模型文件 (.onnx) 复制到 Agent 的模型文件夹中,并参见 添加模型。
操作
对象识别生成 AI: 找到对象 和 AI: 未找到对象 事件,以便在 操作 中使用。
照片
有关照片的信息,请参见 照片。
从反馈中学习
Agent DVR 可以根据您的反馈进行学习,以减少每个摄像头的误报。当检测错误时——夜间看起来像人的灌木,AI 一直称之为鸟的旗帜——您可以告诉 Agent,它将学习在未来抑制该摄像头上类似的检测。所有操作均在 100% 本地 进行:没有图像或数据会离开您的机器,检测模型本身也不会被修改,因此使用起来始终安全且易于重置。
启用
编辑您的摄像头,转到 对象识别 选项卡并开启 从反馈学习。Agent 会在第一次需要时自动下载一个小型嵌入模型。
提供反馈
启用反馈后,由对象识别生成的警报会将检测结果与警报图像一起存储。在 警报面板 中打开警报,您会看到每个检测上方绘制的框,并带有 “我们做对了吗?” 提示:
- 正确: 确认检测。确认的示例保护类似的检测不被抑制。
- 不正确: 拒绝检测。Agent 学习被拒绝检测的外观,针对该摄像头和对象类型。经过几次对相似外观检测的拒绝(至少 3 次),Agent 开始自动抑制匹配的误报。
您可以随时通过再次点击按钮来更改或删除裁决。
“我们做对了吗?” 面板会折叠——点击其标题以隐藏或显示提示和检测覆盖。Agent 会记住您的选择(按浏览器),因此一旦您对摄像头的表现满意,您可以折叠面板,只查看干净的警报图像。折叠面板不会停止学习——抑制仍然有效。要完全停止学习,请关闭摄像头上的 从反馈学习(请注意,这也会停止抑制)。
抑制的警报
抑制是故意保守的——只有当检测明显与您拒绝的示例匹配且不匹配任何确认的示例时,才会被抑制。当 Agent 抑制本来会成为警报的内容时,它会存储一个 抑制的警报,以便没有内容会悄然消失。点击警报面板标题中的 图标以显示或隐藏它们(该图标仅在存在抑制警报时出现;它们会被单独保存,不计入您的正常警报)。
如果 Agent 抑制了不该抑制的内容,请打开抑制的警报并将检测标记为 正确——这会立即解除对类似检测的抑制。
工作原理
Agent 使用通用视觉模型为每个检测创建一个紧凑的数学“指纹”。您的裁决将这些指纹归档为每个摄像头和对象类型的确认或拒绝示例。未来的检测通过相似性与您的示例进行比较——这是 人脸识别 使用的相同方法。您选择的检测模型及其类别保持不变。
重置
学习的反馈存储在 Agent 的 XML 文件夹中的 FeedbackDB.json 中。要重新开始,请调用 clearfeedback API 命令(可选地带上 cameraid 和 label 参数)或停止 Agent 并删除该文件。
将 Ultralytics YOLO 模型转换为 ONNX
Agent DVR 支持用于物体识别的 ONNX 模型文件。您可以下载预训练模型并通过几个步骤将其转换为 ONNX 格式。
下面的示例使用了通过 Ultralytics 提供的 YOLO26s 模型。YOLO26s 是一个较小的通用模型,具有良好的速度/准确性权衡。
先决条件
- Python 3.10 或更高版本
- PATH 中可用 pip
- 互联网连接
- 约 1–2 GB 的可用磁盘空间
步骤 1 – 安装 Ultralytics
pip install ultralytics步骤 2 – 下载 YOLO26s 模型
Ultralytics 在首次使用时会自动下载预训练权重:
yolo detect predict model=yolo26s.pt source=https://ultralytics.com/images/bus.jpg步骤 3 – 转换为 ONNX
下载完成后,将模型导出为 ONNX 格式:
yolo export model=yolo26s.pt format=onnx opset=12 simplify=TruePython 替代方案
from ultralytics import YOLO
model = YOLO("yolo26s.pt")
model.export(format="onnx", opset=12, simplify=True)步骤 4 – 找到 ONNX 文件
导出的
yolo26s.onnxruns/export步骤 5 – 复制到 Agent DVR
将 ONNX 文件移动到您的 Agent DVR ONNX 模型文件夹(在 Agent 服务器上),例如:
Agent\Media\Models\ONNX\步骤 6 – 在 Agent DVR 中添加模型
- 转到 服务器设置 > AI 设置 > AI 模型。
- 点击 配置 并添加新模型。
-
输入名称(例如
),并在下拉菜单中选择yolo26s
文件。.onnx - 将其余选项保留为默认值,然后点击 确定。
- 编辑您的摄像头,打开 物体识别 选项卡,将 服务器 设置为 内部,并选择您的新模型。
本地人脸识别
Agent DVR 支持使用 AI 进行实时实时人脸识别。您需要一个许可证(或有效订阅)才能使用此功能。有关配置 Agent 使用外部 AI 服务器的信息,请参见AI 服务器。
要开始,请编辑您的摄像头并转到人脸识别选项卡。在顶部选择您的 AI 服务器。默认值为内部,这是 Agent DVR 内置的 AI。如果您想使用 AI 服务器,请在服务器设置 - AI 设置 - AI 服务器中添加它,然后在此处选择。
以下详细信息用于配置 Agent DVR 以使用其快速内置 AI。
- 模式:选择您希望 AI 处理视频帧的时间。如果选择间隔,Agent 将使用下面的处理速率字段持续分析您的视频流。
- 叠加:勾选以在实时视频上绘制实时结果。这对于调整置信度限制非常有用。
- 模糊:勾选此项以模糊面孔。
- 使用 GPU:勾选此项以使用您的 GPU 而不是 CPU。
- 处理速率:仅在模式为间隔时使用 - 它控制发送给模型的帧速率。输入 1 表示每秒 1 帧,20 表示每秒 20 帧,或 0.1 表示每 10 秒 1 帧。
- 置信度:这会过滤模型的结果。将此值调高以减少误报,但请注意,这也可能会漏掉人。
- 检查角落:有关更多详细信息,请参阅检查角落。
要识别的面孔
点击编辑面孔以上传您想要识别的人的照片。您可以上传同一个人的多张照片以改善结果。您可以从文件系统上传图像或使用内置摄像头捕捉照片(需要 SSL 或 localhost)。
操作
人脸识别会生成AI: 识别到面孔和AI: 未识别到面孔事件,以便在操作中使用。
照片
有关照片的信息,请参见照片。
本地车牌识别
Agent DVR 支持实时实时车牌识别。您需要一个许可证(或有效订阅)才能使用此功能。有关配置 Agent 使用外部 AI 服务器的信息,请参见AI 服务器。
要开始,请编辑您的摄像头并转到LPR选项卡。在顶部选择您的 AI 服务器。默认值是内部,这是 Agent DVR 内置的 AI。如果您想使用 AI 服务器,请在服务器设置 - AI 设置 - AI 服务器中添加它,然后在此处选择。
以下详细信息用于配置 Agent DVR 及其快速内置 AI。
- 模式:选择您希望 AI 处理视频帧的时间。如果您选择间隔,Agent 将使用下面的处理速率字段持续分析您的视频流。
- 叠加:勾选以在实时视频上绘制实时结果。这对于调整置信度限制非常有用。
- 模糊:勾选此项以模糊检测到的车牌。
- 使用 GPU:勾选此项以使用您的 GPU 而不是 CPU。请注意,这目前仅在 Windows 或 macOS 上有效,因为 GPU 驱动程序和运行时支持。Linux 目前回退到 CPU。
- 处理速率:仅在模式为间隔时使用 - 它控制发送到模型的帧速率。输入 1 表示每秒 1 帧,20 表示每秒 20 帧,或 0.1 表示每 10 秒 1 帧。
- 置信度:这会过滤模型的结果。将其调高以减少误报,但请注意,这也可能会漏掉物体。
- 检查角落:有关更多详细信息,请参见检查角落。
需要查找的车牌
- 车牌:输入一个以逗号分隔的车牌列表或包含车牌的 CSV 文件的 URL。Agent DVR 将为这些车牌生成车牌识别和车牌未识别事件,这些事件可以触发操作。
- 重新加载间隔:设置从 URL 重新加载车牌列表的频率。
- 规范化:调整常被误识别的车牌以改善匹配。
操作
对象识别生成AI: 车牌识别和AI: 车牌未识别事件,以供操作使用。
照片
有关照片的信息,请参见照片。
AI警报过滤
要在 Agent DVR 中设置警报过滤,请按照以下步骤操作:
- 配置并启用运动检测器。为了最小化 CPU 使用,使用简单检测器。确保至少定义一个区域以覆盖您想要监控的区域。
- 在警报标签上,将模式设置为仅操作并启用警报。
- 在录制标签上,将模式设置为警报(如果您想要录制)
- 在对象识别标签上启用对象识别。将模式设置为检测到运动,选择一个模型,然后单击查找以选择要检测的对象,例如人、狗、车等。
- 在标签菜单中转到操作并为事件AI: 找到对象添加一个操作。
选择区域以指定检测对象的位置,例如为您的车道和道路选择不同的区域。例如,选择车道区域仅在检测到汽车时触发警报。
在任务下,单击添加以创建一个警报任务。单击确定两次以确认。
Agent DVR将在检测到运动时处理AI对象识别。如果它在选定区域内检测到指定对象,将触发一个动作以发出警报。如果没有选择区域,将对任何区域触发警报。
要在没有运动检测触发的情况下进行持续的AI对象识别,请将对象识别的模式设置为间隔。监控对硬件资源的影响,并根据需要进行调整。
您可以为不同区域中的不同对象配置多个动作。在动作中使用{AI}标签以引用检测到的对象。
AI过滤器故障排除
如果AI无法有效地过滤您的录像,请考虑以下事项:
- 确保查找设置与可用选项之一匹配。
- 验证Agent左上角显示的主警报开关是否有一个关闭的挂锁,表示活动警报。
- 确认录制模式设置为警报而不是检测。
- 确保警报模式设置为仅动作。
- 尝试降低对象识别下的置信度级别。
- 检查/logs.html以查看错误消息,可能指示服务器问题或网络阻塞。
- 监视AI服务器性能,并确保它不会导致系统超载或超时。
- 如果AI检测到所有对象类别,则可能表示GPU问题。检查GPU驱动程序或切换到基于CPU的AI模块。
AI物体识别
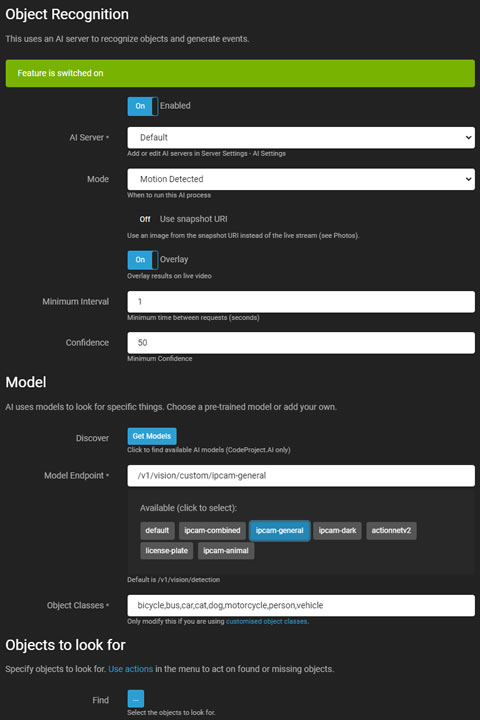
Agent DVR中的对象识别使用我们的本地AI或AI服务器(推荐使用CodeProject.AI)来识别视频流中的特定对象,并可以生成事件、发出警报或作为运动警报的过滤器。
- 启用: 切换以启用或禁用AI处理。
- AI服务器: 从您配置的服务器中选择,或使用默认选项。
- 模式: 选择AI处理的触发器。通过将其设置为无并调用triggerObject仅通过API触发。
- 运动直通: 如果AI服务器宕机并过滤警报,则允许警报不经过过滤直接通过。
- 使用快照URI: 使用来自摄像头的高分辨率帧,而不是当前的实时流帧。
- 调整大小模式: 在将图像发送到AI服务器之前调整图像大小,以减少负载并提高响应时间。
- 叠加: 在实时视频流上显示AI结果。
- 颜色: 叠加的颜色。此设置控制所有AI功能的叠加颜色。
- 最小间隔: 设置服务器请求之间的最小时间。
- 置信度: 设置识别对象的最小置信度水平。
- 检查角落: 有关更多详细信息,请参阅检查角落。
模型
- 发现: 从您的服务器检索已安装的模型(特定于 CodeProject.AI)。
- 模型端点: 从可用模型中选择或使用默认端点。
- 对象类别: 自动填充相关类别或手动输入。
- 查找: 指定要让 AI 检测的对象。
- 忽略静态对象: 忽略在同一位置重复出现的对象。
自定义模型
要将自定义模型添加到 CodeProject.AI,请将模型文件复制到指定目录。通过发现按钮访问,但需手动将对象列表添加到 对象类别。
通过编辑对象识别模块设置更改模型存储目录。
操作
对象识别生成 AI:找到对象 和 AI:未找到对象 事件以供 操作 使用。
照片
有关照片的信息,请参见 照片。
请求人工智能
Agent DVR使用AI服务器(OpenAI/ Claude等)来回答关于摄像头图像的人类可读问题。然后可以生成事件,触发警报,或作为运动警报的过滤器。您需要在服务器设置 - AI服务器 - 询问AI 中完成设置。
您可以在本地服务器的/logs.html中查看日志,以查看何时发送请求。将服务器设置 - 日志记录 - 日志级别设置为Info。
- 已启用:切换以启用或禁用AI进程。
- 提供商:选择要用于处理图像的AI提供商。提供商需要在服务器设置 - AI服务器中配置。如果选择默认值,则将使用第一个配置的提供商。
- 模式:选择AI进程的触发器。通过将其设置为无并调用triggerAskAI来仅通过API触发。
- 运动穿透:如果AI服务器宕机并且过滤警报,则允许警报通过而不进行过滤。
- 使用快照URI:使用摄像头的高分辨率帧而不是当前的实时流帧。
- 调整大小模式:在将图像发送到AI服务器之前调整图像大小,以减少负载并提高响应时间。
- 叠加:在实时视频流上显示AI结果。
- 最小间隔:设置服务器请求之间的最小时间。
AI消息
- 消息:在这里输入您对AI的问题。一些示例:
- 如果在这张图片中看到火,请回复FIRE。如果看到一只狗坐在沙发上,请回复DOG。如果门是开着的,请回复DOOR。如果满足多个条件,请用逗号分隔。
- 如果工作台上的机器灯是红色的,请回复ALERT
- 如果警车停在车道上,请回复POLICE
- 如果地板上有邮件或包裹,请回复MAIL
- 如果看起来有人闯入了我的房子,请回复BREAKIN
- 查找:输入您已指示AI回复的标签。例如FIRE,DOG,DOOR
- 不重复:忽略上次调用AI返回的标签
如上所述,您可以要求消息中满足多个条件,并设置处理每个结果的操作。
操作
场景识别生成询问AI:积极结果事件,用于操作。
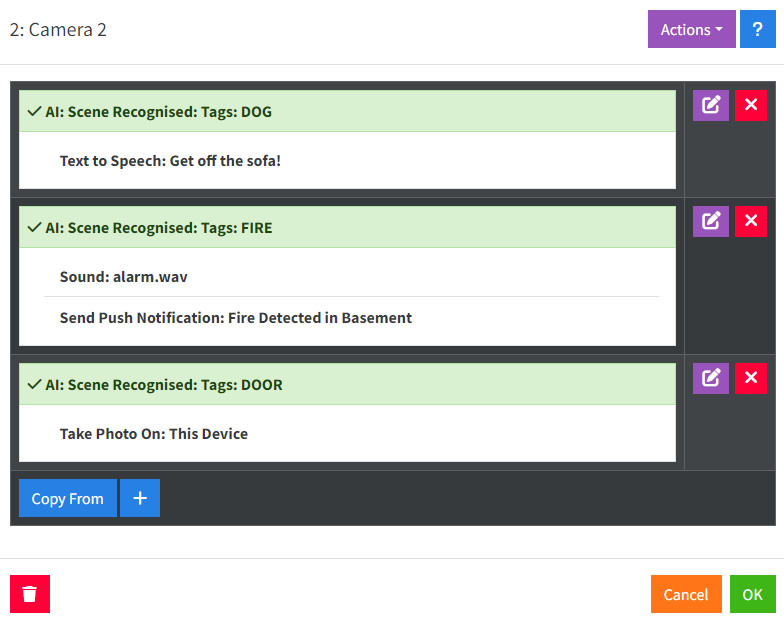
照片
有关照片的信息,请参见照片。请注意,AI目前尚未返回有关图像中物体位置的空间数据,因此裁剪和静态检测目前无法使用。
AI照片
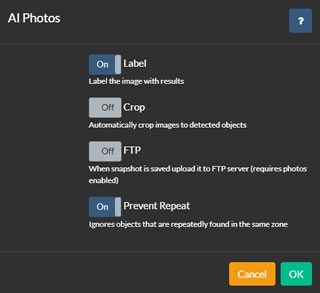
AI处理可以在识别到物体时捕获照片,提供保存、裁剪、FTP上传等选项。
要配置此功能,请在编辑摄像头时,转到每个AI配置选项卡底部的照片选项。启用照片并点击进行配置。
- 标签:Agent在图像上叠加方框并标记检测到的物体。
- 裁剪:Agent将图像裁剪到每个检测到的区域,并保存多个图像,每个区域一个。
- FTP:将保存的图像上传到摄像头配置的FTP服务器。
- 防止重复:Agent避免保存同一物体的多个副本,直到其离开运动区域。
询问 AI:描述
从 v5.8.2.0+ 开始,您可以使用人工智能来描述Agent DVR从摄像头捕获的图像在警报事件中。然后,此描述将与UI中的警报一起存储。要设置此功能,请配置 询问AI 以用于您的摄像头,并在 描述 下方查看底部的选项。
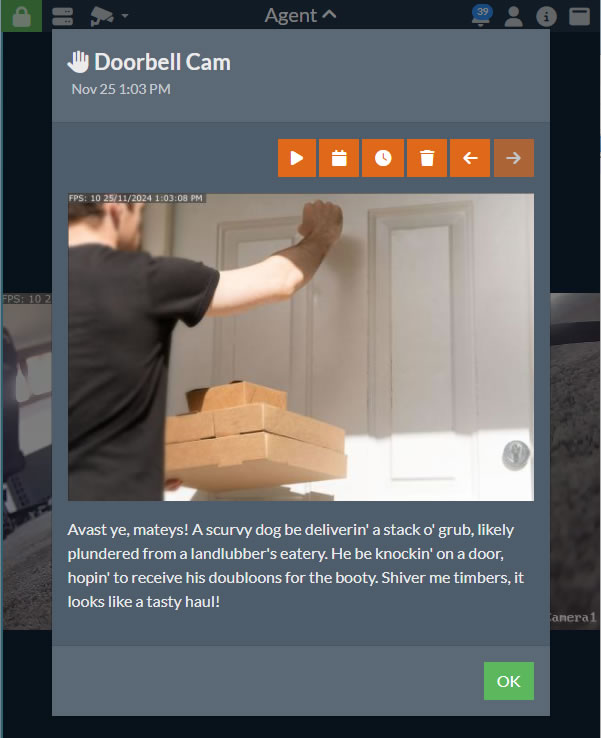
- 提示: 输入要与您的图像一起发送到AI服务器的提示。默认为"描述此图像中正在发生的事情的简短句子"。您也可以尝试一些有趣的内容,例如"用海盗语描述正在发生的事情",就像我们在上面的图像中使用的那样。
- 接下来,请转到 警报 选项卡并勾选 描述 选项。
请注意,您需要启用 询问AI。如果您只希望它描述警报图像,请将 模式 设置为“无”。
一旦您让它注释您的图像,您可以将其与 操作 系统集成,以进行 AI:描述响应已收到。您可以在此操作的任务中使用 {MESSAGE} 和 {AIJSON} 进行其他集成。
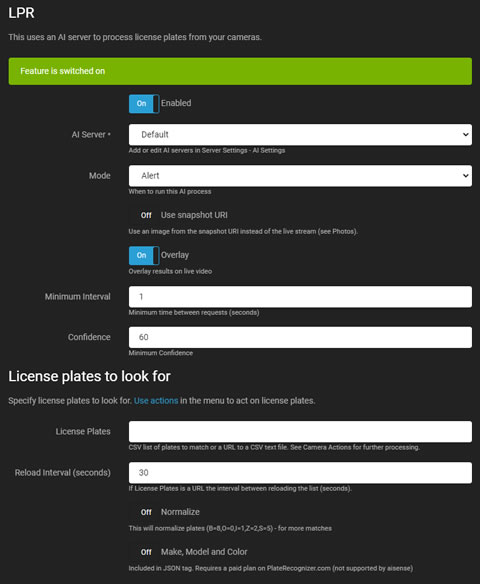
LPR或ALPR
LPR(车牌识别,也称为 ALPR/ANPR)利用 AI 服务器识别和读取视频流中汽车的车牌。它生成事件、发出警报,或作为运动警报的过滤器。
- 启用: 切换以启用或禁用 AI 处理。
- AI 服务器: 从您配置的 服务器 中选择或使用默认选项。Agent DVR 支持通过 CodeProject.AI、PlateRecognizer.com、Gemini 或任何兼容 OpenAI 的视觉 LLM(如 vLLM、Ollama 和 LM Studio)进行 LPR。
- 模式: 选择 AI 处理的触发器。通过将此设置为“无”并调用 triggerLPR 仅通过 API 触发。
- 使用快照 URI: 选择来自摄像头的高分辨率帧,而不是当前的实时流帧。
- 叠加: 将 AI 结果叠加到实时视频流上。
- 最小间隔: 设置服务器请求之间的最小时间以减少负载。
- 置信度: 定义识别车牌的最低置信度水平。
- 检查角落: 有关更多详细信息,请参阅 检查角落。
- 车牌: 输入以逗号分隔的车牌列表或包含车牌的 CSV 文件的 URL。Agent DVR 将为这些车牌生成 识别到的车牌 和 未识别到的车牌 事件,这些事件可以触发操作。
- 重新加载间隔: 设置从 URL 重新加载车牌列表的频率。
- 标准化: 调整常被误识别的车牌以改善匹配。
- 品牌、型号和颜色: 仅在使用支持这些功能的 PlateRecognizer.com 付费计划时启用此项。此功能在免费计划中不包含。详细信息将包含在 Agent DVR 操作的 {AIJSON} 中。
操作
LPR 生成 AI: 识别到车牌 和 AI: 未识别到车牌 事件,以供在 操作 中使用。
照片
有关照片的信息,请参见 照片。
使用 ALPR-Database
您可以与 ALPR-Database.com 设置集成,以存储您的车牌。有关说明,请参见 Agent DVR 与 ALPR-Database。
AI人脸识别
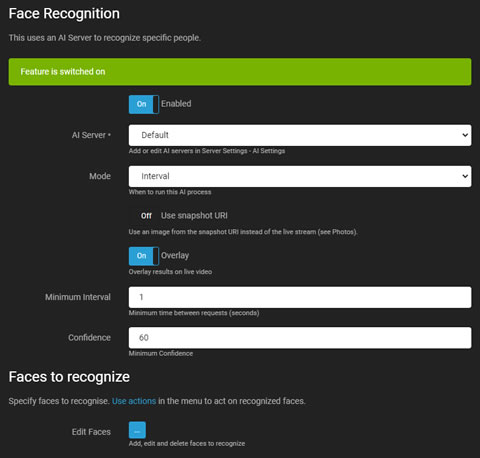
人脸识别利用 AI 服务器(推荐:CodeProject.AI)来识别视频流中的特定人脸。它可以生成事件、发出警报,或作为 运动警报的过滤器。可以通过您的摄像头或上传图像来添加、编辑或删除人脸。有关更多信息,请参见本标签中的 编辑人脸。
- 启用: 切换以启用或禁用 AI 处理。
- AI 服务器: 从您配置的 服务器 中选择,或使用默认选项。
- 模式: 选择 AI 处理的触发器。仅通过将其设置为无并调用 triggerFace 进行 API 触发。
- 使用快照 URI: 选择来自摄像头的高分辨率帧,而不是当前的实时流帧。
- 叠加: 将 AI 结果叠加到实时视频流上。
- 最小间隔: 设置服务器请求之间的最小时间以减少负载。
- 置信度: 定义识别一个人脸的最小置信度水平。
- 检查角落: 有关更多详情,请参阅 检查角落。
- 编辑人脸: 上传图像到服务器数据库以进行识别。确保每张图像中仅可见一个人脸,并且清晰可辨。
操作
人脸识别生成 AI: 人脸识别 和 AI: 人脸未识别 事件以供 操作 使用。
照片
有关照片的信息,请参见 照片。
AI音频识别
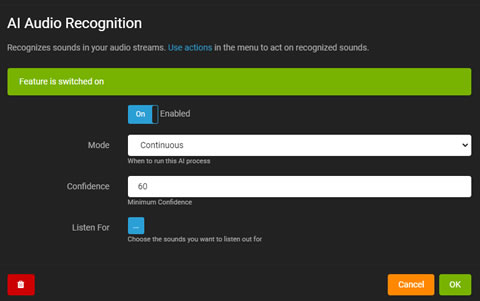
Agent DVR中基于AI的音频识别可以响应来自麦克风或音频流的已识别声音。从服务器设置 - 数据 - AI音频模型(需要iSpyConnect.com账户)下载模型文件以进行设置。
您需要编辑麦克风设置来设置音频识别。如果您有一台带有音频流的摄像机,您可以通过编辑摄像机并选择音频选项卡,然后点击“配置”来访问音频设置。
- 启用:切换以启用或禁用AI进程。
- 模式:选择AI进程的触发器。
- 置信度:设置声音识别的最低置信水平。
- 叠加:在实时音频可视化上显示AI结果。
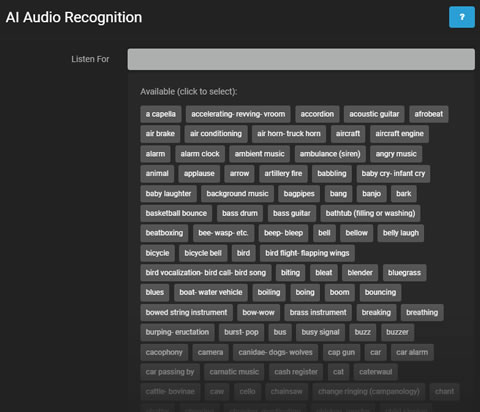
- 监听:选择AI要检测的特定声音。
点击监听显示可用于检测的声音。根据需要选择声音。
使用操作 AI:声音识别来执行声音被识别时的任务。
音频识别还可以用于过滤警报,类似于摄像机。
将操作添加到AI事件
Agent DVR 通过 AI 进程生成事件,可以触发操作。例如,对象识别生成“找到对象”和“未找到对象”的事件。Agent 中的每个 AI 系统都会产生独特的事件。
这些事件可以触发各种操作,例如触发警报、使用对象标签调用 URL、执行程序或将消息发布到 MQTT 服务器。在操作中使用标签 {AI} 表示标签,或使用标签 {AIJSON} 表示来自 CodeProject.AI 的完整 JSON 响应。