AI (人工知能): サーバー
について
Agent DVRは、DeepStack AI、CodeProject AI、PlateRecognizer.com、Claude、Gemini、OpenAI(ChatGPT)などのAIサーバーや、Ollama、vLLM、LM StudioなどのローカルLLMと完全に統合されており、スマートアラートフィルタリング、オブジェクト認識、シーン認識、インテリジェントイベント制御を追加します。
DeepStackおよびCodeProject AIに加えて、同じAPIをサポートする他のAIサーバーも使用できます:
オブジェクト認識とコンピュータビジョン
- https://codeproject.github.io/ - クロスプラットフォームのGPU/CPUベースのAI処理サーバー
- https://docs.platerecognizer.com/ - ナンバープレート認識サーバー(ウェブベースのAPI)
- https://github.com/runningman84/docker-coral-rest-server - RPi(またはLinux/Mac)上のTensorflow-liteモデル、Coral USBスティックによる加速
- https://github.com/robmarkcole/coral-pi-rest-server/ - Flaskアプリを介したCoral USBアクセラレーター上のTensorflow-liteモデル
- https://github.com/xnorpx/blue-candle - 超小型オブジェクト認識サーバー
クラウドAIサービス
- https://platform.openai.com/ - 画像分析とチャットのためのOpenAI API(ChatGPT、GPT-4 Vision)
- https://console.anthropic.com/ - 高度な推論と画像理解のためのAnthropic Claude API
- https://ai.google.dev/ - マルチモーダルAI機能のためのGoogle Gemini API
- https://docs.anthropic.com/ - Claude APIドキュメント
- https://platform.openai.com/docs/ - OpenAI APIドキュメント
- https://ai.google.dev/gemini-api/docs - Gemini APIドキュメント
ローカルAIサーバー(LLMs)
- https://ollama.com/ - Ollama: 大規模言語モデルをローカルで実行
- https://docs.vllm.ai/ - vLLM: 高スループットのLLM推論と提供
- https://lmstudio.ai/ - LM Studio: ローカルLLM用の使いやすいデスクトップアプリ
- https://github.com/ollama/ollama - Ollama GitHubリポジトリ
- https://github.com/vllm-project/vllm - vLLM GitHubリポジトリ
AIモデルの追加
Agent DVRに独自のモデルファイルを追加するには、サーバー設定 > AI設定に移動し、AIモデルの下にある構成をクリックします。Agentには、Agent DVR用にパフォーマンス調整された2つのプリビルドモデルが付属しています。
モデルを構成する前に、それをAgent DVRのモデルフォルダーに追加する必要があります。これは通常、Agent/Media/Models/ONNXにあります(パスはOSによって異なる場合があります)。不明な場合は、モデル追加ページにフルパスが表示されます。Agentは.onnxモデルを使用します。他のAIモデル形式をONNXに変換するには、Pythonツールを使用できます。
モデルを構築してコピーしたら、Agentに追加するのは簡単です - モデルを追加するにはクリックします:
- 名前:モデルに名前を付けます - これはお好きなものにできます。
- モデルファイル:フォルダーにコピーしたモデルファイル名を選択します。
- ラベル:モデルが探すラベル(または「クラス」)のリストをCSV形式で引用符なしで入力します(スペースは自動的にトリムされます)。
- レイアウト:モデルがNCHWかNHWCかを選択します。不明な場合は、ほとんどのモデルはNCHWです。
- チャンネル順序:モデルが画像をRGBまたはBGRで要求するかを選択します。ほとんどのモデルはRGBを使用します。モデルが単一チャンネル(グレースケール)の場合、これは無視されます。
- 正規化:データがモデルで使用される前にどのように正規化されるべきかを選択します。ほとんどのモデルは0-1正規化を使用します(ピクセル値を255で割ります)。
- 画像のパディング:画像を入力寸法に合わせて引き伸ばすか、黒いバーでパディングするかを制御します。通常、精度のために画像をパディングする方が良いです。
- NMSあり:モデルがすでに内部で非最大抑制を実行する場合は、これにチェックを入れます。そうでない場合、AgentがNMSを自分で実行します。NMSは結果の矩形がどのようにフィルタリングされるかを制御します。
- デフォルトNMS:NMSの重なり制限を設定します(デフォルトは45%の重なりです)。
モデルを追加すると、デバイスのオブジェクト認識タブで使用できるようになります。問題が発生した場合は、モデル構成に戻って変更を加えることができます。Agentはモデルファイルの再読み込みもサポートしているため、実行中に新しいバージョンで上書きすることができます。
AIサーバーの設定
AIサーバーを設定するには、メインのAgent DVR UIの左上にあるアイコンをクリックします。次に、設定を構成の下でクリックし、ドロップダウンメニューからAI設定を選択し、AIサーバーの下にある構成をクリックします。
Agent DVRは、オブジェクト認識、顔認識、ALPR(自動ナンバープレート認識)、およびスーパー解像度(強化)を含むさまざまなAI機能のために、CodeProject.AIと統合されています。PlateRecognizer.comもALPRプロバイダーとしてサポートされています。CodeProject.AIはオープンソースで無料であり、ほとんどのプラットフォームと互換性があります。
まず、プラットフォーム用のAIサーバーをインストールし、構成ボタンをクリックしてAgent DVRを接続し、その後追加をクリックします。
必要に応じて、Agent DVRにAIサーバーをいくつでも追加できます。Agent DVR内のカメラは、各機能に対して異なるAIサーバーを使用するように構成することも、すべてのタスクに対して1つのAIサーバーを使用することもできます。
サーバーの構成
- 名前: サーバーに名前を付けてください。例: Cat Catcher。
- AIサーバーURL: AIサーバーのURLを入力してください。例: http://localhost:32168/
- APIキー: 設定されている場合はキーを入力してください(オプション)。
- タイムアウト: サーバーリクエストのタイムアウト(秒単位)。
- 再試行遅延: このサーバーへの失敗したリクエストを再試行する前の時間(秒単位)。
OKをクリックして設定を保存します。
OpenAIを使用する
ビデオフィードで何が起こっているかについての質問に答えるためにOpenAI("Chat GPT")を設定するには、サーバー設定 - AIサーバー に移動し、「Ask AI」の下で「Open AI」を選択します。
- URL: サービスのURLを入力します。デフォルトは「https://api.openai.com/v1/chat/completions」です。
- OpenAI APIキー: OpenAIに登録した後、APIキー ページ に移動し、新しいシークレットキーを生成します。このキーを指定されたフィールドにコピー&ペーストします。
- モデル: 使用するモデルを指定します。デフォルトは gpt-4o です。OpenAIは後日これを削除または変更する可能性があります。
- 最大トークン数: リクエストごとの最大トークン使用量を設定します。問題が発生した場合は、トークン使用に関連している可能性があるため、/logs.html のログを確認してください。
OpenAIが構成されると、カメラフィードで何が起こっているかについて一般的な質問に答えるための使用方法については、Ask AI を参照してください。
Using Claude
ビデオフィードで何が起こっているかについての質問に答えるためにClaude AIを設定するには、サーバー設定 - AIサーバー に移動し、「Ask AI」の下で「Claude」を選択します。
- URL: サービスへのURLを入力します。デフォルトは「https://api.anthropic.com/v1/messages」です。
- Claude APIキー: Claudeにサインアップした後、APIキーのページにアクセスし、新しいシークレットキーを作成します。このキーをフィールドにコピー&ペーストします。
- バージョン: 使用するバージョンを指定します。デフォルトは 2023-06-01 これはAnthropicによっていつか削除または変更される可能性があります。
- モデル: 使用するモデルを指定します。執筆時点のデフォルトは claude-3-sonnet-20240229 です。
- 最大トークン数: これはリクエストごとの最大トークン消費を制御します。問題がある場合は、トークン消費に関連している可能性があるため、/logs.htmlでログを確認してください。
Claudeが構成されたら、カメラフィードで一般的なシナリオを認識する方法については、Ask AIを参照してください。
ジェミニを使用する
ビデオフィードで何が起こっているかについての質問に答えるためにGeminiを設定するには、サーバー設定 - AIサーバー に移動し、「Ask AI」の下で「Gemini」を選択します。
- URL: サービスへのURLを入力します。デフォルトは "https://generativelanguage.googleapis.com" です。
- Gemini APIキー: Geminiにサインアップした後、APIキー ページ にアクセスし、新しいシークレットキーを作成します。このキーをフィールドにコピーして貼り付けます。
- バージョン: 使用するバージョンを指定します。デフォルトは v1beta です。これは後でGoogleによって削除または変更される可能性があります。
- モデル: 使用するモデルを指定します。執筆時点のデフォルトは gemini-1.5-flash です。
- 最大トークン数: リクエストごとの最大トークン消費を制御します。問題がある場合は、トークン消費に関連している可能性があるため、/logs.html のログを確認してください。
Geminiが構成されたら、カメラフィードで一般的なシナリオを認識する方法については、Ask AI を参照してください。
他のLLMサーバーの使用
v6.5.3.0+ からは、Ollama、vLLM、LM Studio のような独自のローカル LLM サーバーを使用して、Agent DVR がカメラからキャプチャした画像を Alert イベントで説明し、ビデオストリームで何が起こっているかについての質問に答えることができます。詳細は AI Describe と Ask AI を参照してください。
ローカル AI サーバーを構成するには、サーバー設定 - AI サーバー に移動し、使用したい LLM の横にある構成ボタンをクリックします(Ollama、vLLM、または LM Studio)。
- URL: LLM サーバーが実行されているエンドポイントを指定します。デフォルトの URL は次のとおりです:
- Ollama:
http://localhost:11434/api/chat - vLLM:
http://localhost:8000/v1/chat/completions - LM Studio:
http://localhost:1234/v1/chat/completions
- Ollama:
- API キー: LLM サーバーが認証を必要とする場合は、ここに API キーを入力します。ほとんどのローカルサーバーは、特に構成されていない限り、これを必要としません。
- モデル: 画像分析に使用するビジョン対応モデルを選択します。このモデルは、すでに LLM サーバーにダウンロードしてロードしておく必要があります。人気のある選択肢には次のものがあります:
- LLaVA モデル(汎用ビジョン)
- Qwen2-VL(高性能)
- Llama 3.2 Vision(Meta の最新)
- 温度: 応答の創造性と正確性を制御します(0.0-1.0)。低い値(0.3-0.4)は、より事実に基づいた一貫した説明を生成します。高い値(0.6-0.8)は、より多様で創造的な応答を生成します。推奨:セキュリティカメラ分析には 0.4。
- 最大トークン: AI の応答における単語/トークンの最大数。高い値はより詳細な説明を可能にしますが、生成に時間がかかります。推奨:詳細な画像分析には 300-500、簡潔な説明には 150-250。
- top_p: 語彙選択を制限することによって応答の多様性を制御します(0.0-1.0)。低い値はより一般的な単語を使用し、高い値はより多様な語彙を許可します。推奨:正確性と自然言語の良いバランスのために 0.9。
- top_k: モデルが次に最も可能性の高い K 個の単語から選択することを制限します。低い値(20-40)はより焦点を絞った応答を生成し、高い値(80-100)はより多様性を許可します。推奨:信頼性のある画像説明には 50。
PlateRecognizer.comを使用する
Agent DVRでLPR(ANPRまたはナンバープレート認識)を設定するには、サーバー設定 - AI設定に移動し、Plate Recognizerの詳細を入力します。無料トライアルにはPlate Recognizerでサインアップしてください。クレジットカードは必要ありません。
ダブルテイクの使用
DoubleTakeは、次の顔認識処理のための統一APIを提供するオープンソースプラットフォームです:
- CompreFace
- Amazon Rekognition
- DeepStack
- CodeProject.AI Server
- Facebox
お好みの顔認識オプションでDoubleTakeをインストールして設定する必要があります。
DoubleTakeの設定が完了したら、Agent DVRを開き、サーバー設定 - AI Serversに移動し、DoubleTakeの隣にある設定ボタンをクリックします。
ダブルテイクサーバーのURL(例:http://localhost:3000/)と、設定している場合はパスワードを入力します。
OKをクリックし、カメラを編集して顔認識に移動します。AIサーバーオプションをDoubleTakeに設定し、必要に応じて顔認識を設定します。
AIモジュールの管理
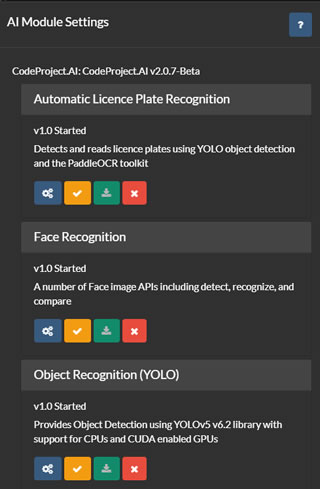
AIサーバーリスト(上記参照)では、AIサーバーの設定、テスト、編集、削除のオプションがあります。[configure]ボタンをクリックして、選択したサーバーにインストールされているモジュールを表示します。
Agent DVRは、サーバーから現在のモジュールリストを取得し、各モジュールのインストール、アンインストール、設定、テストのためのユーザーインターフェースを提供します。Agent DVRは、すべてのデフォルトのCodeProject.UIモジュールに対応していますが、そのうちの一部のみを利用しています。
Agent DVRでALPR(自動ナンバープレート認識)、スーパーレゾリューション、または顔認識を利用するには、このページから各モジュールをインストールする必要があります。通常、これらのモジュールにはデフォルトの設定が適していますが、各モジュールの下にある[configure]アイコンをクリックして設定することもできます。