AI (인공지능): 서버
정보
Agent DVR는 DeepStack AI, CodeProject AI, PlateRecognizer.com, Claude, Gemini, OpenAI (ChatGPT)와 같은 AI 서버 및 Ollama, vLLM, LM Studio와 같은 로컬 LLM과 완벽하게 통합되어 스마트 알림 필터링, 객체 인식, 장면 인식 및 지능형 이벤트 제어를 추가합니다.
DeepStack 및 CodeProject AI 외에도 동일한 API를 지원하는 다른 AI 서버를 사용할 수 있습니다:
객체 인식 및 컴퓨터 비전
- https://codeproject.github.io/ - 크로스 플랫폼 GPU/CPU 기반 AI 처리 서버
- https://docs.platerecognizer.com/ - 번호판 인식 서버 (웹 기반 API)
- https://github.com/runningman84/docker-coral-rest-server - Coral USB 스틱의 가속을 이용한 RPi (또는 Linux/Mac)에서의 Tensorflow-lite 모델
- https://github.com/robmarkcole/coral-pi-rest-server/ - Flask 앱을 통한 Coral USB 가속기에서의 Tensorflow-lite 모델
- https://github.com/xnorpx/blue-candle - 초소형 객체 인식 서버
클라우드 AI 서비스
- https://platform.openai.com/ - 이미지 분석 및 채팅을 위한 OpenAI API (ChatGPT, GPT-4 Vision)
- https://console.anthropic.com/ - 고급 추론 및 이미지 이해를 위한 Anthropic Claude API
- https://ai.google.dev/ - 다중 모드 AI 기능을 위한 Google Gemini API
- https://docs.anthropic.com/ - Claude API 문서
- https://platform.openai.com/docs/ - OpenAI API 문서
- https://ai.google.dev/gemini-api/docs - Gemini API 문서
로컬 AI 서버 (LLMs)
- https://ollama.com/ - Ollama: 대형 언어 모델을 로컬에서 실행
- https://docs.vllm.ai/ - vLLM: 고처리량 LLM 추론 및 제공
- https://lmstudio.ai/ - LM Studio: 로컬 LLM을 위한 사용하기 쉬운 데스크탑 앱
- https://github.com/ollama/ollama - Ollama GitHub 저장소
- https://github.com/vllm-project/vllm - vLLM GitHub 저장소
AI 모델 추가하기
Agent DVR에 자신의 모델 파일을 추가하려면 서버 설정 > AI 설정으로 이동한 후 AI 모델 아래의 구성을 클릭하십시오. Agent는 Agent DVR에 맞게 성능 조정된 두 개의 미리 구축된 모델을 제공합니다.
모델을 구성하기 전에 모델을 Agent DVR의 모델 폴더에 추가해야 합니다. 이 폴더는 일반적으로 Agent/Media/Models/ONNX에 있습니다(경로는 OS에 따라 다를 수 있습니다). 확실하지 않은 경우 모델 추가 페이지에 전체 경로가 표시됩니다. Agent는 .onnx 모델을 사용합니다. Python 도구를 사용하여 다른 AI 모델 형식을 ONNX로 변환할 수 있습니다.
모델을 구축하고 복사한 후, Agent에 추가하는 것은 쉽습니다 - 모델 추가를 클릭하십시오:
- 이름: 모델에 이름을 지정하십시오 - 원하는 이름으로 설정할 수 있습니다.
- 모델 파일: 폴더에 복사한 모델 파일 이름을 선택하십시오.
- 레이블: 모델이 찾는 레이블(또는 "클래스") 목록을 CSV 형식으로 따옴표 없이 입력하십시오(공백은 자동으로 제거됩니다).
- 레이아웃: 모델이 NCHW인지 NHWC인지 선택하십시오. 확실하지 않은 경우 대부분의 모델은 NCHW입니다.
- 채널 순서: 모델이 RGB 또는 BGR 형식의 이미지를 원하는지 선택하십시오. 대부분의 모델은 RGB를 사용합니다. 모델이 단일 채널(그레이스케일)인 경우 이는 무시됩니다.
- 정규화: 데이터가 모델에서 사용되기 전에 어떻게 정규화되어야 하는지 선택하십시오. 대부분의 모델은 0-1 정규화(픽셀 값을 255로 나누기)를 사용합니다.
- 이미지 패딩: 이미지가 입력 크기로 늘어나야 하는지 아니면 검은색 막대로 패딩되어야 하는지를 제어합니다. 일반적으로 정확성을 위해 이미지를 패딩하는 것이 더 좋습니다.
- NMS 있음: 모델이 이미 내부적으로 비최대 억제를 수행하는 경우 이 옵션을 선택하십시오. 그렇지 않으면 Agent가 NMS를 직접 수행합니다. NMS는 결과 사각형이 필터링되는 방식을 제어합니다.
- 기본 NMS: NMS의 중첩 제한기를 설정하십시오(기본값은 45% 중첩입니다).
모델을 추가하면 장치의 객체 인식 탭에서 사용할 수 있습니다. 문제가 발생하면 모델 구성을 다시 돌아가서 변경할 수 있습니다. Agent는 모델 파일을 다시 로드하는 것도 지원하므로 실행 중일 때 새 버전으로 복사할 수 있습니다.
AI 서버 설정
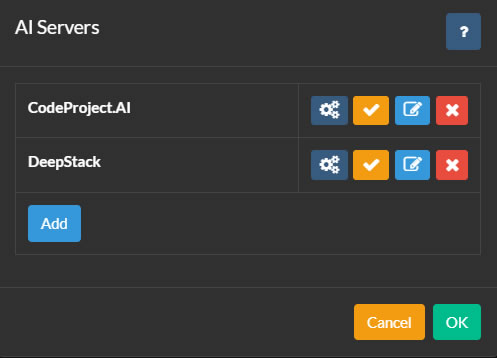
AI 서버를 설정하려면, Agent DVR UI의 왼쪽 상단에 있는 아이콘을 클릭하십시오. 그런 다음 Configuration 아래의 Settings를 클릭하고, 드롭다운 메뉴에서 AI Settings를 선택한 후 AI Servers 아래의 Configure를 클릭하십시오.
Agent DVR은 객체 인식, 얼굴 인식, ALPR(자동 번호판 인식), 슈퍼 해상도(향상) 등 다양한 AI 기능을 위해 CodeProject.AI와 통합됩니다. PlateRecognizer.com도 ALPR 제공업체로 지원됩니다. CodeProject.AI는 오픈 소스이며 무료이고 대부분의 플랫폼과 호환됩니다.
시작하려면, 귀하의 플랫폼에 맞는 AI 서버를 설치하고 Configure 버튼을 클릭한 후 Add를 클릭하여 Agent DVR을 연결하십시오.
필요에 따라 Agent DVR에 여러 AI 서버를 추가할 수 있습니다. Agent DVR의 카메라는 각 기능에 대해 서로 다른 AI 서버를 사용하도록 구성할 수 있으며, 또는 모든 작업에 대해 하나의 AI 서버를 사용할 수 있습니다.
서버 구성하기
- 이름: 서버의 이름을 지정하십시오. 예: Cat Catcher.
- AI 서버 URL: AI 서버의 URL을 입력하십시오. 예: http://localhost:32168/
- API 키: 설정된 경우 키를 입력하십시오(선택 사항).
- 타임아웃: 서버 요청의 타임아웃(초 단위).
- 재시도 지연: 이 서버에 대한 실패한 요청을 재시도하기 전의 시간(초 단위).
OK를 클릭하여 설정을 저장하십시오.
OpenAI를 사용 중입니다.
영상 피드에서 발생하는 일에 대한 질문에 대답하기 위해 OpenAI("Chat GPT")를 설정하려면, 서버 설정 - AI 서버로 이동하여 "Ask AI" 아래에서 "Open AI"를 선택하십시오.
- URL: 서비스의 URL을 입력하십시오. 기본값은 "https://api.openai.com/v1/chat/completions"입니다.
- OpenAI API 키: OpenAI에 등록한 후, API 키 페이지로 이동하여 새로운 시크릿 키를 생성하십시오. 이 키를 지정된 필드에 복사하여 붙여넣으십시오.
- 모델: 사용할 모델을 지정하십시오. 기본값은 gpt-4o입니다. OpenAI는 나중에 이를 제거하거나 변경할 수 있습니다.
- 최대 토큰: 요청 당 최대 토큰 사용량을 설정합니다. 문제가 발생하면 토큰 사용과 관련된 문제일 수 있으므로 /logs.html에서 로그를 확인하십시오.
OpenAI가 구성되면, 카메라 피드에서 발생하는 일에 대한 일반적인 질문에 대답하기 위해 사용하는 방법에 대한 지침은 Ask AI를 참조하십시오.
클라우드 사용하기
비디오 피드에서 발생하는 일에 대한 질문에 대답하기 위해 Claude AI를 설정하려면, - AI Servers로 이동하여 "Ask AI"에서 "Claude"를 선택하십시오.
- URL: 서비스에 대한 URL을 입력하십시오. 기본값은 "https://api.anthropic.com/v1/messages"입니다.
- Claude API Key: Claude에 가입한 후, API Keys Page를 방문하여 새 비밀 키를 생성하십시오. 이 키를 필드에 복사하여 붙여넣으십시오.
- Version: 사용할 버전을 지정하십시오. 기본값은 2023-06-01입니다. 이는 나중에 Anthropic에 의해 제거되거나 변경될 수 있습니다.
- Model: 사용할 모델을 지정하십시오. 작성 시점의 기본값은 claude-3-sonnet-20240229입니다.
- Max Tokens: 이는 요청 당 최대 토큰 소비를 제어합니다. 문제가 발생하면 /logs.html에서 로그를 확인하십시오. 토큰 소비와 관련이 있을 수 있습니다.
Claude가 구성된 후, 카메라 피드에서 일반 시나리오를 인식하는 방법은 Ask AI를 참조하십시오.
제미니를 사용 중입니다.
비디오 피드에서 발생하는 일에 대한 질문에 답변하기 위해 Gemini를 설정하려면, Server Settings - AI Servers로 이동하고 Ask AI 아래에서 "Gemini"을 선택하십시오.
- URL: 서비스의 URL을 입력하십시오. 기본값은 "https://generativelanguage.googleapis.com"입니다.
- Gemini API Key: Gemini에 가입한 후, API Keys Page를 방문하여 새 비밀 키를 생성하십시오. 이 키를 필드에 복사하여 붙여넣으십시오.
- Version: 사용할 버전을 지정하십시오. 기본값은 v1beta입니다. 나중에 Google에 의해 제거되거나 변경될 수 있습니다.
- Model: 사용할 모델을 지정하십시오. 작성 시점의 기본값은 gemini-1.5-flash입니다.
- Max Tokens: 이는 요청 당 최대 토큰 소비를 제어합니다. 문제가 발생하면 /logs.html의 로그를 확인하십시오. 이는 토큰 소비와 관려이 있을 수 있습니다.
Gemini가 구성된 후에는 카메라 피드에서 일반 시나리오를 인식하는 방법에 대해 알아보기 위해 Ask AI를 참조하십시오.
다른 LLM 서버 사용하기
v6.5.3.0+부터는 vLLM, Ollama 및 LM Studio와 같은 로컬 LLM 서버를 사용하여 Agent DVR이 카메라에서 캡처한 이미지를 Alert 이벤트에서 설명하고 비디오 스트림에서 발생하는 일에 대한 질문에 답변할 수 있습니다. AI Describe 및 Ask AI를 참조하십시오.
로컬 AI 서버를 구성하려면 서버 설정 - AI Servers로 이동하여 사용하려는 LLM 옆에 있는 구성 버튼을 클릭하십시오 (Ollama, vLLM 또는 LM Studio).
- URL: LLM 서버가 실행되고 있는 엔드포인트를 지정하십시오. 기본 URL은 다음과 같습니다:
- Ollama:
http://localhost:11434/api/chat - vLLM:
http://localhost:8000/v1/chat/completions - LM Studio:
http://localhost:1234/v1/chat/completions
- Ollama:
- API Key: LLM 서버에 인증이 필요한 경우 여기에서 API 키를 입력하십시오. 대부분의 로컬 서버는 특별히 구성되지 않는 한 이 키를 요구하지 않습니다.
- Model: 이미지 분석에 사용할 비전 기능 모델을 선택하십시오. 이 모델은 이미 LLM 서버에 다운로드하여 로드해야 합니다. 인기 있는 선택은 다음과 같습니다:
- LLaVA 모델 (일반 목적 비전)
- Qwen2-VL (고성능)
- Llama 3.2 Vision (Meta의 최신)
- Temperature: 응답의 창의성 대 정확성을 제어합니다 (0.0-1.0). 낮은 값 (0.3-0.4)은 더 사실적이고 일관된 설명을 생성합니다. 높은 값 (0.6-0.8)은 더 다양하고 창의적인 응답을 생성합니다. 추천: 보안 카메라 분석을 위해 0.4.
- Max Tokens: AI의 응답에서 최대 단어/토큰 수입니다. 높은 값은 더 자세한 설명을 허용하지만 생성하는 데 더 오랜 시간이 걸립니다. 추천: 자세한 이미지 분석을 위해 300-500, 간단한 설명을 위해 150-250.
- top_p: 어휘 선택을 제한하여 응답 다양성을 제어합니다 (0.0-1.0). 낮은 값은 더 일반적인 단어를 사용하고, 높은 값은 더 다양한 어휘를 허용합니다. 추천: 정확성과 자연어의 좋은 균형을 위해 0.9.
- top_k: 모델이 가장 가능성이 높은 다음 K개의 단어 중에서 선택하도록 제한합니다. 낮은 값 (20-40)은 더 집중된 응답을 생성하고, 높은 값 (80-100)은 더 다양한 응답을 허용합니다. 추천: 신뢰할 수 있는 이미지 설명을 위해 50.
PlateRecognizer.com
Agent DVR에서 LPR (ANPR 또는 번호판 인식)을 구성하려면, 서버 설정 - AI 설정으로 이동하여 Plate Recognizer 아래에 세부 정보를 입력하십시오. Plate Recognizer에서 무료 평가판에 가입하십시오. 신용카드는 필요하지 않습니다.
DoubleTake 사용하기
DoubleTake는 다음을 사용하여 얼굴 인식을 처리하기 위한 통합 API를 제공하는 오픈 소스 플랫폼입니다:
- CompreFace
- Amazon Rekognition
- DeepStack
- CodeProject.AI Server
- Facebox
선호하는 얼굴 인식 옵션으로 DoubleTake를 설치하고 구성해야 합니다.
DoubleTake가 설정되면 Agent DVR을 열고 서버 설정 - AI Servers로 이동한 다음 DoubleTake 옆의 구성 버튼을 클릭합니다.
당신의 doubletake 서버의 URL(예: http://localhost:3000/)과 설정한 경우 비밀번호를 입력합니다.
확인을 클릭한 후 카메라를 편집하고 얼굴 인식으로 이동합니다. AI 서버 옵션을 DoubleTake로 설정하고 필요에 따라 얼굴 인식을 구성합니다.
AI 모듈 관리하기
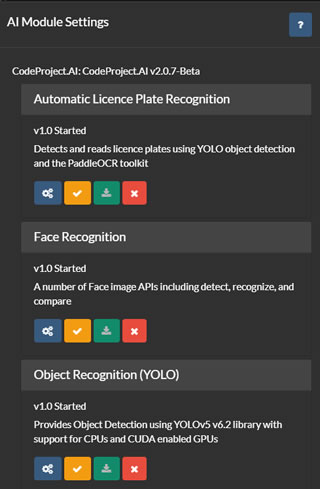
AI 서버 목록 (위에서 참조함)에서 AI 서버를 구성, 테스트, 편집 및 제거할 수 있는 옵션이 있습니다. 구성 버튼을 클릭하여 선택한 서버에 설치된 모듈을 표시할 수 있습니다.
Agent DVR은 서버에서 현재 모듈 목록을 검색하고 각 모듈을 설치, 제거, 구성 및 테스트하기 위한 사용자 인터페이스를 제공합니다. 모든 기본 CodeProject.UI 모듈에 대한 지원이 제공되지만, Agent DVR은 이러한 모듈의 일부만 사용합니다.
Agent DVR에서 ALPR (자동 번호판 인식), 슈퍼 해상도 또는 얼굴 인식을 사용하려면 해당 모듈을 이 페이지에서 설치해야 합니다. 일반적으로 기본 설정은 이러한 모듈에 적합하지만, 각 모듈 아래의 아이콘을 클릭하여 구성할 수도 있습니다.