IA: Serveurs
À propos
Agent DVR s'intègre entièrement avec des serveurs d'IA comme DeepStack AI, CodeProject AI, PlateRecognizer.com, Claude, Gemini, OpenAI (ChatGPT) et des LLM locaux comme Ollama, vLLM et LM Studio pour ajouter un filtrage intelligent des alertes, la reconnaissance d'objets, la reconnaissance de scènes et un contrôle d'événements intelligent.
En plus de DeepStack et CodeProject AI, vous pouvez également utiliser d'autres serveurs d'IA qui prennent en charge la même API :
Reconnaissance d'Objets & Vision par Ordinateur
- https://codeproject.github.io/ - Serveur de traitement AI basé sur GPU/CPU multiplateforme
- https://docs.platerecognizer.com/ - Serveur de reconnaissance de plaques d'immatriculation (API basée sur le web)
- https://github.com/runningman84/docker-coral-rest-server - Modèles Tensorflow-lite sur un RPi (ou Linux/Mac) avec accélération via une clé USB Coral
- https://github.com/robmarkcole/coral-pi-rest-server/ - Modèles Tensorflow-lite sur un accélérateur USB Coral via une application Flask
- https://github.com/xnorpx/blue-candle - Serveur de reconnaissance d'objets super petit
Services d'IA Cloud
- https://platform.openai.com/ - API OpenAI (ChatGPT, GPT-4 Vision) pour l'analyse d'images et le chat
- https://console.anthropic.com/ - API Anthropic Claude pour le raisonnement avancé et la compréhension d'images
- https://ai.google.dev/ - API Google Gemini pour des capacités d'IA multimodales
- https://docs.anthropic.com/ - Documentation de l'API Claude
- https://platform.openai.com/docs/ - Documentation de l'API OpenAI
- https://ai.google.dev/gemini-api/docs - Documentation de l'API Gemini
Serveurs d'IA Locaux (LLMs)
- https://ollama.com/ - Ollama : Exécutez des modèles de langage de grande taille localement
- https://docs.vllm.ai/ - vLLM : Inférence et service LLM à haut débit
- https://lmstudio.ai/ - LM Studio : Application de bureau facile à utiliser pour les LLM locaux
- https://github.com/ollama/ollama - Dépôt GitHub d'Ollama
- https://github.com/vllm-project/vllm - Dépôt GitHub de vLLM
Ajouter des modèles d'IA
Pour ajouter vos propres fichiers de modèle dans Agent DVR, allez dans Paramètres du serveur > Paramètres de l'IA et cliquez sur Configurer sous Modèles d'IA. Agent est livré avec deux modèles préconstruits qui ont été optimisés pour Agent DVR.
Avant de configurer un modèle, vous devrez l'ajouter au dossier Modèles d'Agent DVR. Celui-ci se trouve généralement à Agent/Media/Models/ONNX (le chemin peut varier selon le système d'exploitation). Le chemin complet est affiché sur la page Ajouter un modèle si vous n'êtes pas sûr. Agent utilise des modèles .onnx. Vous pouvez convertir d'autres formats de modèles d'IA en ONNX à l'aide d'outils Python.
Une fois que vous avez construit et copié le modèle, l'ajout à Agent est facile - cliquez pour ajouter un modèle :
- Nom : Donnez un nom à votre modèle - cela peut être n'importe quoi.
- Fichier du modèle : Sélectionnez le nom de fichier du modèle que vous avez copié dans le dossier.
- Étiquettes : Entrez une liste d'étiquettes (ou "classes") que votre modèle recherche au format CSV sans guillemets (les espaces sont automatiquement supprimés).
- Disposition : Sélectionnez si votre modèle est NCHW ou NHWC. La plupart des modèles sont NCHW si vous n'êtes pas sûr.
- Ordre des canaux : Sélectionnez si votre modèle souhaite des images en RGB ou BGR. La plupart des modèles utilisent RGB. Si votre modèle est à canal unique (niveaux de gris), cela sera ignoré.
- Normaliser : Sélectionnez comment les données doivent être normalisées avant d'être utilisées dans votre modèle. La plupart des modèles utilisent une normalisation de 0 à 1 (diviser les valeurs des pixels par 255).
- Pad Image : Cela contrôle si l'image doit être étirée aux dimensions d'entrée ou remplie avec des barres noires. Il est généralement préférable de remplir les images pour plus de précision.
- A un NMS : Cochez ceci si votre modèle effectue déjà une suppression non maximale en interne. Sinon, Agent effectuera lui-même le NMS. Le NMS contrôle comment les rectangles de résultats sont filtrés.
- NMS par défaut : Définissez le limiteur de chevauchement pour le NMS (le défaut est un chevauchement de 45 %).
Une fois que vous avez ajouté votre modèle, il sera disponible pour une utilisation dans l'onglet Reconnaissance d'objets de votre appareil. Si vous avez des problèmes, vous pouvez revenir à la configuration du modèle et apporter des modifications. Agent prend également en charge le rechargement du fichier modèle, vous pouvez donc le remplacer par une nouvelle version pendant qu'il fonctionne.
Configurer les serveurs d'IA
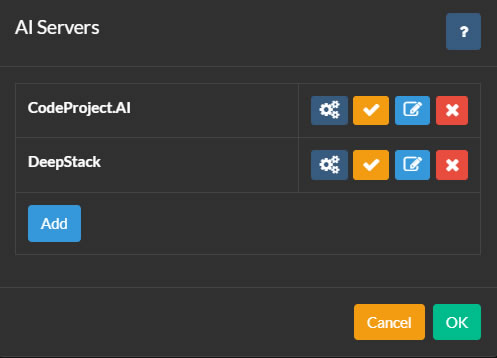
Pour configurer les serveurs AI, cliquez sur l'icône en haut à gauche de l'interface principale d'Agent DVR. Ensuite, cliquez sur Paramètres sous Configuration, sélectionnez Paramètres AI dans le menu déroulant, et cliquez sur Configurer sous Serveurs AI.
Agent DVR s'intègre avec CodeProject.AI pour diverses fonctionnalités AI, y compris la reconnaissance d'objets, la reconnaissance faciale, l'ALPR (Reconnaissance Automatique de Plaques d'Immatriculation), et la super résolution (amélioration). PlateRecognizer.com est également pris en charge en tant que fournisseur ALPR. CodeProject.AI est open source, gratuit et compatible avec la plupart des plateformes.
Pour commencer, installez un serveur AI pour votre plateforme et connectez Agent DVR à celui-ci en cliquant sur le bouton Configurer puis Ajouter.
Vous pouvez ajouter autant de serveurs AI à Agent DVR que nécessaire. Les caméras dans Agent DVR peuvent être configurées pour utiliser différents serveurs AI pour chaque fonction, ou vous pouvez utiliser un seul serveur AI pour toutes les tâches.
Configuration de votre serveur
- Nom : Nommez votre serveur, par exemple, Attrapeur de Chats.
- URL du serveur AI : Entrez l'URL de votre serveur AI, par exemple, http://localhost:32168/
- Clé API : Entrez votre clé si configurée (optionnel).
- Délai d'expiration : Le délai d'expiration en secondes pour les requêtes au serveur.
- Délai de nouvelle tentative : Le temps en secondes avant de réessayer une requête échouée à ce serveur.
Cliquez sur OK pour enregistrer vos paramètres.
Utilisation d'OpenAI
Pour configurer OpenAI ("Chat GPT") afin de répondre aux questions sur ce qui se passe dans votre flux vidéo, accédez à Paramètres du serveur - Serveurs IA et sélectionnez "Open AI" sous Demander à l'IA.
- URL : Entrez l'URL du service. Par défaut, c'est "https://api.openai.com/v1/chat/completions".
- Clé API OpenAI : Après vous être inscrit auprès d'OpenAI, rendez-vous sur la page des clés API et générez une nouvelle clé secrète. Copiez et collez cette clé dans le champ spécifié.
- Modèle : Spécifiez le modèle à utiliser. Par défaut, c'est gpt-4o. OpenAI pourrait le supprimer ou le modifier ultérieurement.
- Jetons Max : Cela définit l'utilisation maximale de jetons par requête. Si vous rencontrez des problèmes, vérifiez les journaux à /logs.html car cela pourrait être lié à l'utilisation des jetons.
Une fois OpenAI configuré, consultez Demander à l'IA pour des instructions sur comment l'utiliser pour répondre à des questions générales sur ce qui se passe dans votre flux de caméra.
Utilisation de Claude
Pour configurer Claude AI afin de répondre aux questions sur ce qui se passe dans votre flux vidéo, accédez aux Paramètres du Serveur - Serveurs IA et sélectionnez "Claude" sous Demander à l'IA.
- URL : Entrez l'URL du service. Par défaut, c'est "https://api.anthropic.com/v1/messages".
- Clé API Claude : Après vous être inscrit à Claude, visitez la Page des Clés API et créez une nouvelle clé secrète. Copiez et collez cette clé dans le champ.
- Version : Spécifiez la version à utiliser. Par défaut, c'est 2023-06-01. Cela peut être supprimé ou modifié à un moment donné par Anthropic.
- Modèle : Spécifiez le modèle à utiliser. Par défaut, au moment de la rédaction, c'est claude-3-sonnet-20240229.
- Jetons Max : Cela contrôle la dépense maximale de jetons par requête. Vérifiez les journaux à /logs.html si vous rencontrez des problèmes car cela pourrait être lié à la dépense de jetons.
Une fois Claude configuré, consultez Demander à l'IA pour savoir comment l'utiliser pour reconnaître des scénarios généraux dans votre flux de caméra.
Utilisation de Gemini
Pour configurer Gemini afin de répondre aux questions sur ce qui se passe dans votre flux vidéo, accédez aux Paramètres du Serveur - Serveurs IA et sélectionnez "Gemini" sous Demander à l'IA.
- URL : Entrez l'URL du service. Par défaut, c'est "https://generativelanguage.googleapis.com".
- Clé API de Gemini : Après vous être inscrit à Gemini, visitez la Page des Clés API et créez une nouvelle clé secrète. Copiez et collez cette clé dans le champ.
- Version : Spécifiez la version à utiliser. Par défaut, c'est v1beta. Cela peut être supprimé ou modifié à un moment donné par Google.
- Modèle : Spécifiez le modèle à utiliser. Par défaut, au moment de la rédaction, c'est gemini-1.5-flash.
- Jetons Max : Cela contrôle la dépense maximale de jetons par demande. Vérifiez les journaux à /logs.html si vous rencontrez des problèmes car cela pourrait être lié à la dépense de jetons.
Une fois que Gemini est configuré, consultez Demander à l'IA pour savoir comment l'utiliser pour reconnaître des scénarios généraux dans votre flux de caméra.
Utiliser d'autres serveurs LLM
À partir de v6.5.3.0+, vous pouvez utiliser vos propres serveurs LLM locaux (comme vLLM, Ollama et LM Studio) pour décrire les images capturées par Agent DVR depuis vos caméras dans les événements d'alerte et répondre aux questions sur ce qui se passe dans vos flux vidéo. Voir AI Describe et Ask AI.
Pour configurer un serveur AI local, allez dans les paramètres du serveur - Serveurs AI et cliquez sur le bouton Configurer à côté du LLM que vous souhaitez utiliser (Ollama, vLLM ou LM Studio).
- URL : Spécifiez le point de terminaison où votre serveur LLM est en cours d'exécution. Les URL par défaut sont :
- Ollama :
http://localhost:11434/api/chat - vLLM :
http://localhost:8000/v1/chat/completions - LM Studio :
http://localhost:1234/v1/chat/completions
- Ollama :
- Clé API : Si votre serveur LLM nécessite une authentification, entrez la clé API ici. La plupart des serveurs locaux ne nécessitent pas cela, sauf s'ils sont spécifiquement configurés.
- Modèle : Sélectionnez le modèle capable de vision à utiliser pour l'analyse d'image. Vous devez avoir déjà téléchargé et chargé ce modèle dans votre serveur LLM. Les choix populaires incluent :
- Modèles LLaVA (vision à usage général)
- Qwen2-VL (hautes performances)
- Llama 3.2 Vision (dernier de Meta)
- Température : Contrôle la créativité par rapport à l'exactitude des réponses (0.0-1.0). Des valeurs plus basses (0.3-0.4) produisent des descriptions plus factuelles et cohérentes. Des valeurs plus élevées (0.6-0.8) génèrent des réponses plus variées et créatives. Recommandé : 0.4 pour l'analyse des caméras de sécurité.
- Max Tokens : Nombre maximum de mots/tokens dans la réponse de l'IA. Des valeurs plus élevées permettent des descriptions plus détaillées mais prennent plus de temps à générer. Recommandé : 300-500 pour une analyse d'image détaillée, 150-250 pour des descriptions brèves.
- top_p : Contrôle la diversité des réponses en limitant la sélection de vocabulaire (0.0-1.0). Des valeurs plus basses utilisent des mots plus courants, des valeurs plus élevées permettent un vocabulaire plus varié. Recommandé : 0.9 pour un bon équilibre entre précision et langage naturel.
- top_k : Limite le modèle à choisir parmi les K mots suivants les plus probables. Des valeurs plus basses (20-40) produisent des réponses plus ciblées, des valeurs plus élevées (80-100) permettent plus de variété. Recommandé : 50 pour des descriptions d'images fiables.
Utilisation de PlateRecognizer.com
Pour configurer la LPR (ANPR ou Reconnaissance de Plaques d'Immatriculation) dans Agent DVR, allez dans Paramètres du Serveur - Paramètres IA et saisissez les détails sous Plate Recognizer. Inscrivez-vous pour un essai gratuit sur Plate Recognizer. Aucune carte de crédit requise.
- URL : Saisissez l'URL du service. Par défaut, il s'agit de "https://api.platerecognizer.com/v1/plate-reader/", ou utilisez votre propre serveur si vous hébergez votre propre instance.
- Token : Après vous être inscrit sur Plate Recognizer, rendez-vous sur la page de compte et copiez le jeton API.
- Régions : Laissez vide pour la valeur par défaut ou saisissez une liste CSV de régions.
- Config : Saisissez des valeurs de configuration supplémentaires à partir de la documentation si nécessaire.
Utiliser DoubleTake
DoubleTake est une plateforme open source qui fournit une API unifiée pour le traitement de la reconnaissance faciale utilisant :
- CompreFace
- Amazon Rekognition
- DeepStack
- CodeProject.AI Server
- Facebox
Vous devrez installer et configurer DoubleTake avec vos options de reconnaissance faciale préférées.
Une fois DoubleTake configuré, ouvrez Agent DVR et allez dans les paramètres du serveur - Serveurs AI et cliquez sur le bouton Configurer à côté de DoubleTake.
Entrez l'URL de votre serveur doubletake (par exemple http://localhost:3000/) et votre mot de passe si configuré.
Cliquez sur OK, puis modifiez une caméra et allez dans Reconnaissance Faciale. Réglez l'option Serveur AI sur DoubleTake et configurez la reconnaissance faciale si nécessaire.
Gestion des modules d'IA
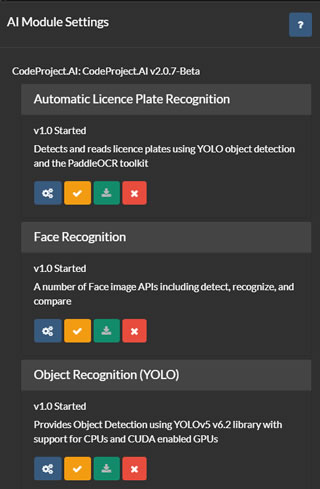
Dans la liste des serveurs d'IA (référencée ci-dessus), vous avez des options pour configurer, tester, éditer et supprimer les serveurs d'IA. Cliquez sur le bouton de configuration pour afficher les modules disponibles ou installés sur le serveur sélectionné.
Agent DVR récupère la liste des modules actuels à partir de votre serveur et offre une interface utilisateur pour installer, désinstaller, configurer et tester chaque module. Un support est fourni pour tous les modules CodeProject.UI par défaut, bien qu'Agent DVR n'utilise qu'un sous-ensemble de ceux-ci.
Pour utiliser la reconnaissance automatique des plaques d'immatriculation (ALPR), la super résolution ou la reconnaissance faciale dans Agent DVR, vous devrez installer le module correspondant depuis cette page. En général, les paramètres par défaut suffisent pour ces modules, mais vous pouvez les configurer en cliquant sur l'icône sous chaque module.